
 ���Ɍ����W�j��GAN���������������V�wһ���c�ݶȑ��P ��Ӗ������
�r�g��2025-05-28 ��Դ���A���hҊ
���Ɍ����W�j��GAN���������������V�wһ���c�ݶȑ��P ��Ӗ������
�r�g��2025-05-28 ��Դ���A���hҊ
���Ɍ����W�j��GAN���� 2014 ������ԁ����ѳɞ�����ģ���I�����Ҫ��ʯ�����Ļ� ��˼�뿴�ƺ��Σ��s���R���T��Ӗ����������ģʽ�������ݶ���ʧ��ը��һϵ�І� �}�����Č��۽��ڃɂ���������V���о������������Ե��P�I���g —— �V�wһ��
��Spectral Normalization�� �� �ݶȑ��P�� Gradient Penalty�� ����̽ӑ������� �fͬ����������GAN��Ӗ���������c�����|����
һ�� ���}������ ��ʲôGAN�y��Ӗ����
���yGANӖ���r���Єe�� D �������� G ��һ�N��Ͳ��ĵ��Pϵ��������r�� D �� G ���ڸ����в����M�������ڌ��HӖ���Ѕs�������F�����}��
�Єe���^�����^�������ݶ���Ϣȱʧ Ӗ���^���в�ƽ�⣬�Єe���^�M��
ģʽ������ Mode Collapse��
�pʧ�������ٷ�ӳģ���|��
��ˣ��о��߂�����˶�N���t�������������Єe����“�О�”��ʹ��Ӗ���^�̸���ƽ ����
�����V�wһ����Spectral Normalization��
�� ԭ������
�V�wһ����һ�Nͨ�^�s���Єe��ÿһ�ә��ص�����殐ֵ���V������ ���Ķ����ƾW�j Lipschitz �����ļ��g��
������֮����ͨ�^��ÿһ�ӵę��� W �wһ���飺
$W_ {SN} = \frac{W}{\sigma(W)} $ ���� σ(W) �Ǿ�� W ������殐ֵ��
✅ ���c
�����Єe���� Lipschitz ��������ֹ�ݶȱ�ը �Ք����죬Ӗ��������
�o���~��ij��������c�ݶȑ��P��ͬ��
�A ������SN-GAN
�V�wһ���״��� Miyato ������ 2018 ���Փ����������������� SN-GAN �У�Ч���@ �����ڂ��y GAN��
�����ݶȑ��P��Gradient Penalty��
�� ԭ������
�ݶȑ��P�ĺ���˼���ǣ� �s���Єe����ݔ����ݶȲ���̫�Ķ����� Lipschitz �B �m�ԡ�
�� WGAN-GP �У����P헱����ӵ��˓pʧ�����У�
LGP = λ ⋅ (��∇D()�� 2 − 1)2
���� x^ ���挍�ӱ��c���ɘӱ�֮�g�IJ�ֵ�c�� λ �Ǚ���ϵ����
✅ ���c
���Կ����Єe�����ݶ��О� �m���ڸ��N GAN �ܘ�
����Ч����ģʽ�������}
⚠ ȱ�c
������Ӌ����s��
�ݶȹ�Ӌ���ܲ����������x�� λ
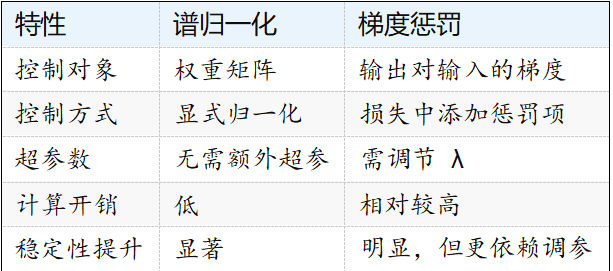
�ġ��V�wһ�� vs �ݶȑ��P
�塢�ϲ��ԣ��V�wһ�� + �ݶȑ��P
�ڌ��H�У����߽Y��ʹ�ÿ���ȡ�L�a�̡��V�wһ�����ƾW�j���w�߶ȣ����ݶȑ��P�t�� ���s��ݔ��ݔ�������жȡ�
�� �ϲ��Ժ���˼·��
1. ���Єe����ʹ���V�wһ�����s��ÿһ�ӵ� Lipschitz ����
2. �ړpʧ�����������ݶȑ��P헌�ݔ��ݔ��׃���M���~��s��
3. ͨ�^�m���{���ݶȑ��P�ę��� λ , �Mһ������Ӗ��������
���`��
ģ���ڳ����Ք���ƽ��
�Єe�����^�M�ϣ������������ڃ���
�� CIFAR-10��Ce lebA �Ȕ������ϣ�FID �÷����@���½�
����PyTorch ʾ�����δ��a��

�ߡ����Y
�V�wһ���c�ݶȑ��P���|�϶��Ǟ��ˌ��F�Єe����ƽ�����ƣ������քe��“�������g” ��“ݔ����g”�ɂ��ǶȽ�Q GAN ��Ӗ���������Ԇ��}����ʹ���@�ɷN���g������ Ч��
��� GAN Ӗ�������� ����ģʽ����
�������ɘӱ��|��
�ڽ��� GAN �ܘ��OӋ�У��@�N “�p���Uʽ”�����t������ ���ɞ����ģ�Ϳɿ��Ե��� Ч�ֶΡ�
 �n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�ԴǶ��ʽ GPU �ĈD�μ��ټ��g�������Ɍ����W�j��GAN���������������V�wһ���c�ݶȑ��P Ƕ��ʽ���r����ϵ�y��RTOS���л���P�I���΄��{�Ȳ���������������ĕr�������z�y�c����λģ���OӋ�����W����RL���ڙC����ץȡ�΄��е�ϡ�誄���c�n�̌WǶ��ʽ���̎�����е��΄��w���cؓ�d�����㷨�OӋ�c�������¼��ӵ�Ƕ��ʽϵ�y�����OӋ���Ă������ɘӵ����� Zephyr RTOS ��Ƕ��ʽ�{�� Mesh �W�j���c�OӋ�c����Ҏģģ��Ӗ���е� ZeRO �������c��Ͼ���ͨ�ʼn��s��W��(FL)�е��ݶ���ע���c����[˽���oƽ�����
�n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�ԴǶ��ʽ GPU �ĈD�μ��ټ��g�������Ɍ����W�j��GAN���������������V�wһ���c�ݶȑ��P Ƕ��ʽ���r����ϵ�y��RTOS���л���P�I���΄��{�Ȳ���������������ĕr�������z�y�c����λģ���OӋ�����W����RL���ڙC����ץȡ�΄��е�ϡ�誄���c�n�̌WǶ��ʽ���̎�����е��΄��w���cؓ�d�����㷨�OӋ�c�������¼��ӵ�Ƕ��ʽϵ�y�����OӋ���Ă������ɘӵ����� Zephyr RTOS ��Ƕ��ʽ�{�� Mesh �W�j���c�OӋ�c����Ҏģģ��Ӗ���е� ZeRO �������c��Ͼ���ͨ�ʼn��s��W��(FL)�е��ݶ���ע���c����[˽���oƽ�����

