
 ��ģ�B��ģ��(VLMM)�еĿ�ģ�B���R�pʧ�����O Ӌ�c�{����
�r�g��2025-05-09 ��Դ���A���hҊ
��ģ�B��ģ��(VLMM)�еĿ�ģ�B���R�pʧ�����O Ӌ�c�{����
�r�g��2025-05-09 ��Դ���A���hҊ
1 ����
�S���˹����ܼ��g�Ŀ��ٰlչ ����ģ�B��ģ��(Vision-Language Multi modal Models, VLMM)�ѳɞ鮔ǰ�о��ğ� �c���@�ģ���܉�ͬ�r̎��������ҕ�X�c�Z����Ϣ ���ڈD���������ɡ�ҕ�X���𡢿�ģ�B�z�����΄���չ�F������ ������Ȼ�� �������Ч�،��R��ͬģ�B�ı�ʾ���g ����Ȼ������ģ�����ܵ��P�I���𡣱��Č�����̽ӑVLMM�е� ��ģ�B���R�pʧ�����OӋ�c�{���ԡ�
2 ��ģ�B���R�ĺ�������
��ģ�B�W�����R�ĺ��Ć��}��������Բ�ͬģ�B(��D����ı�)�ı�ʾ��ͬһ���Z�x���g�б���һ�¡����w���� ������
1. ģ�B���ϣ�ҕ�X���Z�Ԕ���������ȫ��ͬ�ĽyӋ����
2. �Z�x�����R����ͬ�����ڲ�ͬģ�B�еı��_��ʽ�ͳ���Ӵβ�ͬ
3. ����Ҏģ���ҕ�X���ı������Ŀ�����ͨ����ƥ��
3 ������ģ�B���R�pʧ�����OӋ
1. ���ȌW���pʧ(Contrastive Loss)
���ȌW���ѳɞ��ģ�B���R���������� �������˼�����������ӱ����ı�ʾ���x �����hؓ�ӱ����ı�ʾ���x��
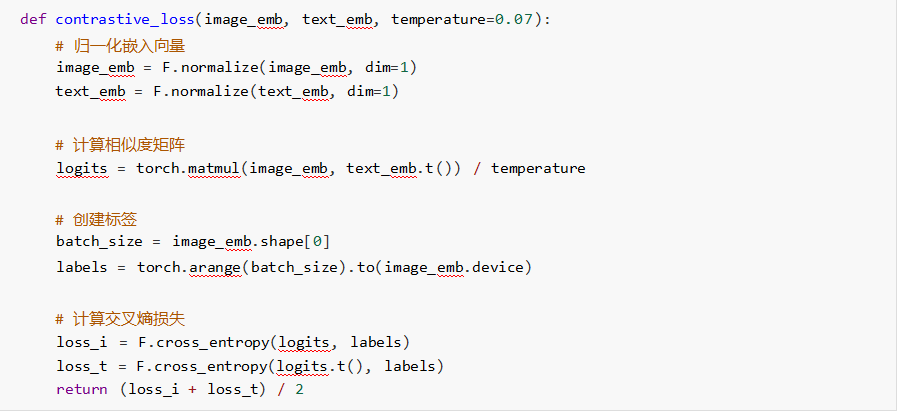
2. ��Ԫ�M�pʧ(Triplet Loss)
��Ԫ�M�pʧͨ�^�^�c�����ӱ���ؓ�ӱ��Č��ȁ�W����ģ�B���R��

3. ��ģ�BͶӰ�pʧ(Cross-Modal Projection Loss)
ԓ����ͨ�^��С��ģ�B�gͶӰ�`��팍�F���R��

4. �������ݔ�ēpʧ(Optimal Transport Loss)
�������ݔ��Փ����ģģ�B�g�ķֲ����R��

4 �����R����
1. �Ӵλ����R(Hierarchical Alignment)
�ڲ�ͬ����Ӵ��ό�ʩ���R�s����
. �ֲ��������R(��D��^���c���~) . ȫ���Z�x���R(��DƬ���w�c����)
2. ע�����������R(Attention-Guided Alignment)
���ÿ�ģ�Bע�����C�ưl�Fģ�B�g�ļ����Ȍ����Pϵ��

'
3. �������R(Adversarial Alignment)
�����Єe���W�j��ʹ�ɷNģ�B�ı�ʾ�y�ԅ^�֣�
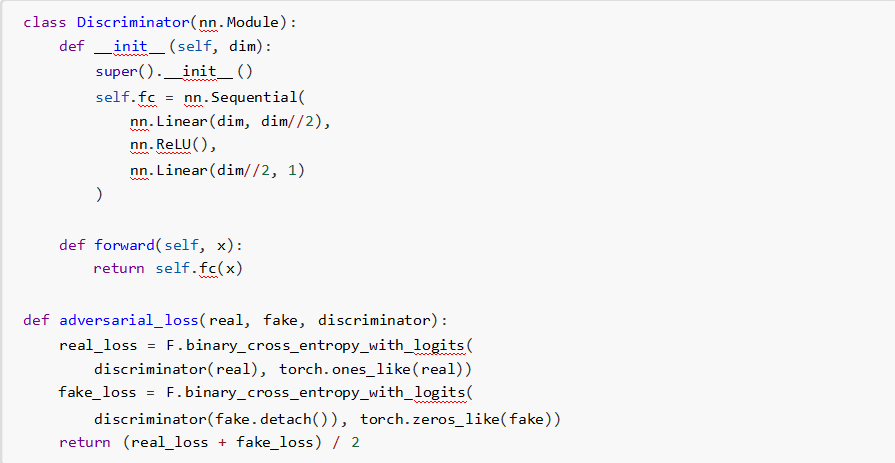
5 �{����
1. ���A���{
1. ģ�B�ض��{ ���Ϊ��{��ģ�B���a��
2. ���{ ���̶����a����ʹ���^С�W���� �����c������ģ�B��������
2. �u�Mʽ���
���Տĵӵ�플ӵ��������W�j������

3. �n�̌W��(Curriculum Learning)
�ĺ��Θӱ��_ʼ ���������y�ȣ�
��ʹ�ø������ȡ����α����ĈD�� ��u������s�����ͳ������
4. ���΄��όW��
ͬ�r�����������P�΄գ�

��ģ�B�z��
�D���������� ҕ�X����
���`���h
1. ������������ҕ�X���ı�������ʩ�f�{����������
2. �ضȅ����{�������ȌW���еĜضȅ�����Ҫ�м��{��
3. ؓ�ӱ��ھ�ʹ���yؓ�ӱ�(hard negatives)��������Ч��
4. �O��ָ�� �����˓pʧֵ ��߀����ۙ��ģ�B�z���ʴ_�ʵ�ֱ��ָ��
�����
1. �ӑB���R���ԣ������ӱ��������m���{�����R����
2. �o�O�����R ���p�ٌ���ע��������ه
3. ��ģ�B֪�R���s����С�͌��Rģ������ȡ֪�R
4. ��̖�Y�ϣ��Y�Ϸ�̖�����������R�ɽ����
�Y�Z
��ģ�B���R�Ƕ�ģ�B��ģ�ͳɹ����P�I��ͨ�^�����OӋ�ēpʧ�������{���� ���҂�������Ч�ؘ�Ӳ�ͬģ�B֮�g ���Z�x���ϡ�δ���S��ģ��Ҏģ�IJ����U��͌��R���g�ij��m���� ����ģ�B�����c�����������Mһ������ �����˙C ������AI�����_���µĿ����ԡ�
 �n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�ԴǶ��ʽ߅��Ӌ�������FPGA�ӑB���������ü��g���`��ģ�B��ģ��(VLMM)�еĿ�ģ�B���R�pʧ�����O Ӌ�cǶ��ʽϵ�y�з���ʧ�ԃȴ棨NVM����ĥ�p�����㷨�OӋ�̼���ܛ����Ӳ���ڶ��x�����ܺ͑��È����ϴ����@���^AIģ�����s���g���������ϵăȴ�ռ���c����ƽ�⌍�`�����әC���W����Ƕ��ʽϵ�y�еĿ����Է����cԭ�͌��FǶ��ʽLinux���r�Ը��죺PREEMPT_RT�a���cXenomai�p���D�W�j(GNN)�����W�O���Pϵ�����еđ����c����Ƕ��ʽ߅��Ӌ�������FPGA�ӑB���������ü��g���`������ȌW���Į����z�y�㷨�ڕr�g���Д����еđ���
�n�̷������A���hҊ��NXP�Ƴ�i.MX8M Plus�_�l�c���`�n�̷���������HarmonyOSϵ�y�����W�_�l�����n�̣��n�̷�����HaaS EDU K1�_�l�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�ԴǶ��ʽ߅��Ӌ�������FPGA�ӑB���������ü��g���`��ģ�B��ģ��(VLMM)�еĿ�ģ�B���R�pʧ�����O Ӌ�cǶ��ʽϵ�y�з���ʧ�ԃȴ棨NVM����ĥ�p�����㷨�OӋ�̼���ܛ����Ӳ���ڶ��x�����ܺ͑��È����ϴ����@���^AIģ�����s���g���������ϵăȴ�ռ���c����ƽ�⌍�`�����әC���W����Ƕ��ʽϵ�y�еĿ����Է����cԭ�͌��FǶ��ʽLinux���r�Ը��죺PREEMPT_RT�a���cXenomai�p���D�W�j(GNN)�����W�O���Pϵ�����еđ����c����Ƕ��ʽ߅��Ӌ�������FPGA�ӑB���������ü��g���`������ȌW���Į����z�y�㷨�ڕr�g���Д����еđ���

