��ǰλ�ã���� > �W���YԴ > �v������ > ��������W����CRL���ڹ��I(y��)�C���˹�������ϵ�y(t��ng)�еěQ��·����(y��u)��

 ��������W����CRL���ڹ��I(y��)�C���˹�������ϵ�y(t��ng)�еěQ��·����(y��u)��
�r�g��2025-04-08 ��Դ���A���hҊ
��������W����CRL���ڹ��I(y��)�C���˹�������ϵ�y(t��ng)�еěQ��·����(y��u)��
�r�g��2025-04-08 ��Դ���A���hҊ
�S�����I(y��)�Ԅӻ��İl(f��)չ�����I(y��)�C���������a�еđ���Խ��Խ�V����Ȼ�����C�����ڏ��s�h(hu��n)�����\�Еr�y����F(xi��n)���ϣ���ο��١���Ч�،��F(xi��n)���������ɞ��P�I���}�����y(t��ng)������ه���A�OҎ(gu��)�t�ҽ��y���m�����s��׃�Ĺ��ψ���������������W����Causal Reinforcement Learning, CRL���ij��F(xi��n)�����Q�@һ���}�ṩ���µ�˼·��
һ����������W����CRL������
��������W����CRL���nj���������c�����W����Y�ϵ�һ�N���d��������ͨ�^��������Pϵ�ķ��������������w���õ�����h(hu��n)���е�׃����������ã��Ķ��������ɿ������߿ɽ���ԵěQ�ߡ��c���y(t��ng)�����W����ȣ�CRL���H�Pע��B(t��i)�̈́�����߀���]������Pϵ���܉������ޘӱ��ЌW���L������Pϵ����ߛQ�ߵ������ԡ�
�������I(y��)�C���˹�������ϵ�y(t��ng)�ĬF(xi��n)���c����(zh��n)
�ڹ��I(y��)���a�У��C���˹��Ͽ��܌������aͣ������ɾ��pʧ���F(xi��n)�еĹ�������ϵ�y(t��ng)����ه���A�OҎ(gu��)�t�ҽ��y���m�����s��׃�Ĺ��ψ��������⣬���y(t��ng)�������挦δ֪���ϕr�������֟o�ߣ��o�������ҵ��(y��u)���ޏ�·����
����CRL�ڹ�������ϵ�y(t��ng)�еěQ��·����(y��u)��
��һ������Pϵ��ģ
�ڹ��I(y��)�C���˹�������ϵ�y(t��ng)�У�CRL������Ҫ���C�����\�Эh(hu��n)���е�����Pϵ�M�н�ģ��ͨ�^���������cϵ�y(t��ng)��B(t��i)����������(sh��)��(j��)������ָ�������֮�g������Pϵ�������Y�����ģ�ͣ�SCM�������磬�������Â�������(sh��)��(j��)���Д���ϵĿ���ԭ����늙C�^���������������^���ɢ�����
�������Q��·����(y��u)��
���ڽ��������ģ�ͣ�CRL�܉�ӑB(t��i)�{���Q��·���������ϰl(f��)���r��ϵ�y(t��ng)ͨ�^����������ٶ�λ����ԭ���Y�Ϗ����W���㷨���Ĵ������ܵ��ޏͲ������x���(y��u)·�������磬��늙C���ψ����У�CRL���Ը���(j��)����ԭ���x���؆�늙C���{���������Q�����Ȳ��ԣ���ͨ�^ģ�M�͌��H�yԇ������(y��u)�����ԡ�
��������(sh��)��(j��)�ӵ����m���W��
CRL��һ���@����(y��u)�����܉���δ֪����Pϵ����r�£�ͨ�^��(sh��)��(j��)�ӵķ�ʽ�W������Pϵ���ڹ��I(y��)�C���˹�������ϵ�y(t��ng)�У���ʹ��ʼ����Pϵ�����_��CRLҲ����ͨ�^�c�h(hu��n)���Ľ������W�������c�ޏͲ���֮�g������Pϵ���Ķ����F(xi��n)���m����(y��u)����
�ġ�CRL�ڹ��I(y��)�C���˹�������ϵ�y(t��ng)�еđ��Ã�(y��u)��
��һ����ߛQ��Ч��
CRLͨ�^�������p���˛Q���^���еğoЧ�Lԇ���܉���ٶ�λ����ԭ���x���(y��u)�ޏ�·�����@�������˹�������ϵ�y(t��ng)��푑��ٶȺ��ޏ�Ч�ʡ�
����������ϵ�y(t��ng)������
CRL�܉��m�����s��׃�Ĺ��ψ�������ʹ���挦δ֪���ϕr��Ҳ��ͨ�^��������ҵ������Ľ�Q�������@�N������ʹ�ù��I(y��)�C�����ڏ��s�h(hu��n)�����\�и��ӷ�(w��n)����
���������;S�o�ɱ�
ͨ�^��(y��u)���Q��·����CRL�p���˹����ޏ�����ĕr�g���YԴ���Ķ������˾S�o�ɱ������⣬CRL�����m���W������߀���Ԝp�ٌ����ҽ�����ه��
�塢���a���F(xi��n)ʾ��
���˸��õ�����CRL�ڹ��I(y��)�C���˹�������ϵ�y(t��ng)�еđ��ã�������һ������Maze-based-CRL�Ĵ��aʾ����ԓ���aչʾ����Ό����֪�R���뵽�݆T-�uՓ��ģ���У�ͨ�^������탞(y��u)���Q��·����
�h(hu��n)�����b

���]ʹ��conda���b̓�M�h(hu��n)�������]ʹ��Ubuntuϵ�y(t��ng)��
CRL���aʾ��
������һ��������CRL���aʾ����չʾ������ڹ�������ϵ�y(t��ng)�Ќ��F(xi��n)��������W����
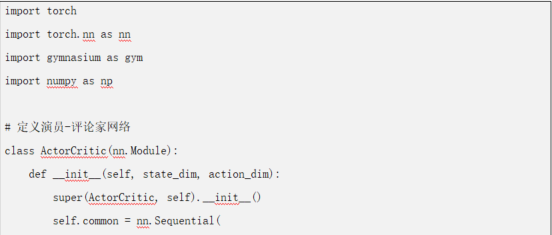

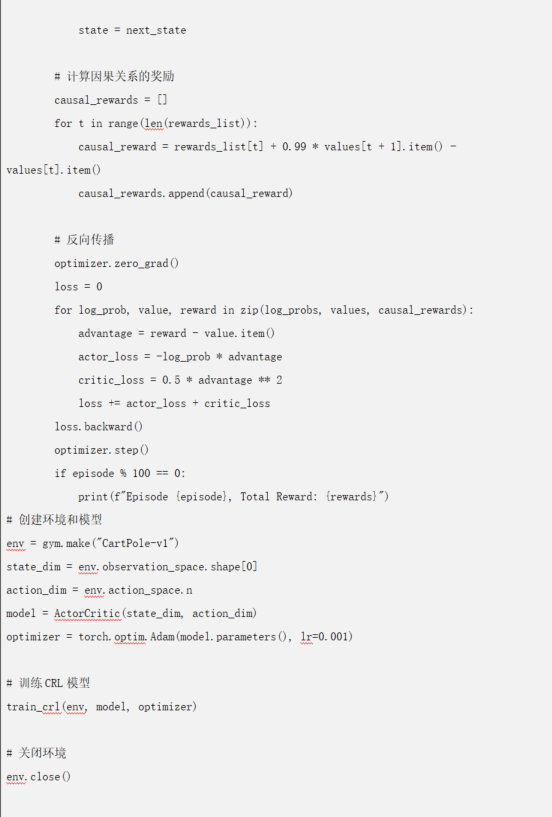
CRL���aʾ��
������һ��������CRL���aʾ����չʾ������ڹ�������ϵ�y(t��ng)�Ќ��F(xi��n)��������W����
 �n�̷������A���hҊ(li��n)��NXP�Ƴ�i.MX8M Plus�_�l(f��)�c���`�n�̷���������HarmonyOSϵ�y(t��ng)����(li��n)�W(w��ng)�_�l(f��)����(zh��n)�n�̣��n�̷�����HaaS EDU K1�_�l(f��)�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�Դ���������ռ����g�ğo늳�Ƕ��ʽϵ�y(t��ng)�OӋ���ĭh(hu��n)�������������W����CRL���ڹ��I(y��)�C���˹�������ϵ�y(t��ng)�еěQǶ��ʽϵ�y(t��ng)�л���Ӳ����������AES-GCM�������܃�(y��u)����Transformerģ��ϡ�軯Ӗ���c�������ټ��g����(zh��n)�����ܼ���(li��n)�W(w��ng)��(ji��)�c�ğo��վͨ�š������ڷ���ɢ�����ģ���������g���ȣ�INT8�c���M�ƾW(w��ng)�j��BNN�� �ľ����c����CHERI�ܘ���Ƕ��ʽϵ�y(t��ng)�ȴ氲ȫ�C�Ʒ��o�о�(li��n)��W����߅���O���е��[˽���o�cͨ��Ч��ƽ���������RISC-Vָ��Č��r����ϵ�y(t��ng)�Д���(y��u)�ȼ��{���㷨��(y��u)TLS 1.3 ���YԴ�����O���е��p�������F(xi��n)
�n�̷������A���hҊ(li��n)��NXP�Ƴ�i.MX8M Plus�_�l(f��)�c���`�n�̷���������HarmonyOSϵ�y(t��ng)����(li��n)�W(w��ng)�_�l(f��)����(zh��n)�n�̣��n�̷�����HaaS EDU K1�_�l(f��)�̳̣����n��ҕ�l��Դ�a���°�C�Z�Ծ���֮�����Z��ҕ�l�̳��ذ�ٛ�ͣ�Ƕ��ʽ���rֵ2000Ԫ��Ƕ��ʽ���b�̴̳�Y�����M�ͣ����㶮Ƕ���rֵ1000Ԫ������ARMϵ��ҕ�l������̳����r���t���������¡�ARM�n���n�Ì�䛾��A��ҕ�l���M�Iȡ���Ⱥ�Դ���������ռ����g�ğo늳�Ƕ��ʽϵ�y(t��ng)�OӋ���ĭh(hu��n)�������������W����CRL���ڹ��I(y��)�C���˹�������ϵ�y(t��ng)�еěQǶ��ʽϵ�y(t��ng)�л���Ӳ����������AES-GCM�������܃�(y��u)����Transformerģ��ϡ�軯Ӗ���c�������ټ��g����(zh��n)�����ܼ���(li��n)�W(w��ng)��(ji��)�c�ğo��վͨ�š������ڷ���ɢ�����ģ���������g���ȣ�INT8�c���M�ƾW(w��ng)�j��BNN�� �ľ����c����CHERI�ܘ���Ƕ��ʽϵ�y(t��ng)�ȴ氲ȫ�C�Ʒ��o�о�(li��n)��W����߅���O���е��[˽���o�cͨ��Ч��ƽ���������RISC-Vָ��Č��r����ϵ�y(t��ng)�Д���(y��u)�ȼ��{���㷨��(y��u)TLS 1.3 ���YԴ�����O���е��p�������F(xi��n)

