��(d��ng)ǰλ�ã���� > Ƕ��ʽ��Ӗ(x��n) > Ƕ��ʽ�W(xu��)��(x��) > �v������ > ��N��Ҋ��IOģ��
 ��N��Ҋ��IOģ��
�r(sh��)�g��2017-09-22 ��Դ��δ֪
��N��Ҋ��IOģ��
�r(sh��)�g��2017-09-22 ��Դ��δ֪
��N��Ҋ��IOģ��
��һ���֣��������Ďׂ�(g��)��Ҫ����
(1) �Ñ����g�̓�(n��i)�˿��g
�F(xi��n)�ڲ���ϵ�y(t��ng)���Dz���̓�M�惦(ch��)������ô��(du��)32λ����ϵ�y(t��ng)���ԣ����Č�ַ���g��̓�M�惦(ch��)���g����4G��2��32�η���������ϵ�y(t��ng)�ĺ����ǃ�(n��i)�ˣ���(d��)������ͨ�đ�(y��ng)�ó������L���ܱ��o(h��)�ă�(n��i)����g��Ҳ���L����Ӳ���O(sh��)������Й�(qu��n)�ޡ����˱��C�Ñ��M(j��n)�̲���ֱ�Ӳ�����(n��i)�ˣ�kernel�������C��(n��i)�˵İ�ȫ������ϵ�y(t��ng)��̓�M���g���֞�ɲ��֣�һ���֞��(n��i)�˿��g��һ���֞��Ñ����g��ᘌ�(du��)linux����ϵ�y(t��ng)���ԣ����ߵ�1G�ֹ�(ji��)����̓�M��ַ0xC0000000��0xFFFFFFFF��������(n��i)��ʹ�ã��Q���(n��i)�˿��g�������^�͵�3G�ֹ�(ji��)����̓�M��ַ0x00000000��0xBFFFFFFF����������(g��)�M(j��n)��ʹ�ã��Q���Ñ����g��
��(n��i)�˿��gKernel
��3G-4G��
�����g
��0G-3G��
(2) �M(j��n)���ГQ
���˿����M(j��n)�̵Ĉ�(zh��)�У���(n��i)�˱����������������CPU���\(y��n)�е��M(j��n)�̣����֏�(f��)��ǰ�����ij��(g��)�M(j��n)�̵Ĉ�(zh��)�С��@�N�О鱻�Q���M(j��n)���ГQ����˿����f���κ��M(j��n)�̶����ڲ���ϵ�y(t��ng)��(n��i)�˵�֧�����\(y��n)�еģ����c��(n��i)�˾o�����P(gu��n)�ġ�
������һ��(g��)�M(j��n)�̵��\(y��n)���D(zhu��n)����һ��(g��)�M(j��n)�����\(y��n)�У��@��(g��)�^���н�(j��ng)�^�����@Щ׃����
����1. ����̎��C(j��)�����ģ���������Ӌ(j��)��(sh��)���������Ĵ�����
����2. ����PCB��Ϣ��
����3. ���M(j��n)�̵�PCB��������(y��ng)���(du��)�У���;w����ij�¼��������(du��)�С�
����4. �x����һ��(g��)�M(j��n)�̈�(zh��)�У���������PCB��
����5. ����(n��i)������Ĕ�(sh��)��(j��)�Y(ji��)��(g��u)��
����6. �֏�(f��)̎��C(j��)�����ġ�
ע��������֮���Ǻܺ��YԴ
(3) �M(j��n)�̵�����
���ڈ�(zh��)�е��M(j��n)�̣������ڴ���ijЩ�¼�δ�l(f��)������Ո(q��ng)��ϵ�y(t��ng)�YԴʧ�����ȴ�ij�N��������ɡ���(sh��)��(j��)��δ���_(d��)��o�¹������ȣ��t��ϵ�y(t��ng)�Ԅ�(d��ng)��(zh��)������ԭ�Z(Block)��ʹ�Լ����\(y��n)�Р�B(t��i)׃?y��u)�������B(t��i)����Ҋ���M(j��n)�̵��������M(j��n)��������һ�N����(d��ng)�О飬Ҳ���ֻ��̎���\(y��n)�БB(t��i)���M(j��n)�̣��@��CPU�����ſ��܌����D(zhu��n)��������B(t��i)����(d��ng)�M(j��n)���M(j��n)��������B(t��i)���Dz�ռ��CPU�YԴ�ġ�
(4) �ļ�������
�ļ���������File descriptor����Ӌ(j��)��C(j��)�ƌW(xu��)�е�һ��(g��)�g(sh��)�Z����һ��(g��)���ڱ���ָ���ļ������õij����
�����ļ�����������ʽ����һ��(g��)��ؓ(f��)����(sh��)����(sh��)�H�ϣ�����һ��(g��)����ֵ��ָ���(n��i)�˞�ÿһ��(g��)�M(j��n)�����S�o(h��)��ԓ�M(j��n)�̴��_�ļ���ӛ䛱�����(d��ng)������_һ��(g��)�F(xi��n)���ļ����߄�(chu��ng)��һ��(g��)���ļ��r(sh��)����(n��i)�����M(j��n)�̷���һ��(g��)�ļ����������ڳ����O(sh��)Ӌ(j��)�У�һЩ�漰�ӵij���������(hu��)���@���ļ�������չ�_�������ļ��������@һ��������ֻ�m����UNIX��Linux�@�ӵIJ���ϵ�y(t��ng)��
(5) ����I/O
���� I/O �ֱ��Q����(bi��o)��(zh��n) I/O�������(sh��)�ļ�ϵ�y(t��ng)��Ĭ�J(r��n) I/O �������Ǿ��� I/O���� Linux �ľ��� I/O �C(j��)���У�����ϵ�y(t��ng)��(hu��)�� I/O �Ĕ�(sh��)��(j��)�������ļ�ϵ�y(t��ng)��퓾��棨 page cache ���У�Ҳ�����f����(sh��)��(j��)��(hu��)�ȱ���ؐ������ϵ�y(t��ng)��(n��i)�˵ľ��_�^(q��)�У�Ȼ��ŕ�(hu��)�IJ���ϵ�y(t��ng)��(n��i)�˵ľ��_�^(q��)��ؐ����(y��ng)�ó���ĵ�ַ���g��
���� I/O ��ȱ�c(di��n)��
��(sh��)��(j��)�ڂ�ݔ�^������Ҫ�ڑ�(y��ng)�ó����ַ���g�̓�(n��i)���M(j��n)�ж�Δ�(sh��)��(j��)��ؐ�������@Щ��(sh��)��(j��)��ؐ������������ CPU �Լ���(n��i)���_�N�Ƿdz���ġ�
�ڶ����֣�IOģ��
�����ѽ�(j��ng)�ᵽ����(du��)��һ��IO�L������read�e��������(sh��)��(j��)��(hu��)�ȱ���ؐ������ϵ�y(t��ng)��(n��i)�˵ľ��_�^(q��)�У�Ȼ��ŕ�(hu��)�IJ���ϵ�y(t��ng)��(n��i)�˵ľ��_�^(q��)��ؐ����(y��ng)�ó���ĵ�ַ���g�������f����(d��ng)һ��(g��)read�����l(f��)���r(sh��)������(hu��)��(j��ng)�v�ɂ�(g��)�A�Σ�
����1. �ȴ���(sh��)��(j��)��(zh��n)�� (Waiting for the data to be ready)
2. ����(sh��)��(j��)�ă�(n��i)�˿�ؐ���M(j��n)���� (Copying the data from the kernel to the process)
������?y��n)��@�ɂ�(g��)�A�Σ�linuxϵ�y(t��ng)�a(ch��n)����������N�W(w��ng)�j(lu��)ģʽ�ķ�����
����- ���� I/O��blocking IO��
����- ������ I/O��nonblocking IO��
����- I/O ��·��(f��)�ã� IO multiplexing��
����- ��̖(h��o)�(q��)��(d��ng) I/O�� signal driven IO��
- ���� I/O��asynchronous IO��
(1) ����I/O
��linux�У�Ĭ�J(r��n)��r�����е�socket����blocking��һ��(g��)���͵��x�������̴�����@�ӣ�

������(d��ng)�Ñ��M(j��n)���{(di��o)����recvfrom�@��(g��)ϵ�y(t��ng)�{(di��o)�ã�kernel���_ʼ��IO�ĵ�һ��(g��)�A�Σ���(zh��n)�䔵(sh��)��(j��)����(du��)�ھW(w��ng)�j(lu��)IO���f���ܶ��r(sh��)��(sh��)��(j��)��һ�_ʼ߀�]�е��_(d��)�����磬߀�]���յ�һ��(g��)������UDP�����@��(g��)�r(sh��)��kernel��Ҫ�ȴ����Ĕ�(sh��)��(j��)���������@��(g��)�^����Ҫ�ȴ���Ҳ�����f��(sh��)��(j��)����ؐ������ϵ�y(t��ng)��(n��i)�˵ľ��_�^(q��)������Ҫһ��(g��)�^�̵ġ������Ñ��M(j��n)���@߅������(g��)�M(j��n)�̕�(hu��)����������(d��ng)Ȼ�����M(j��n)���Լ��x�������������(d��ng)kernelһֱ�ȵ���(sh��)��(j��)��(zh��n)����ˣ����͕�(hu��)����(sh��)��(j��)��kernel�п�ؐ���Ñ��(n��i)�棬Ȼ��kernel���ؽY(ji��)�����Ñ��M(j��n)�̲Ž��block�Ġ�B(t��i)�������\(y��n)��������
�������ԣ�blocking IO�����c(di��n)������IO��(zh��)�еăɂ�(g��)�A�ζ���block�ˡ�
(2) ������I/O
linux�£�����ͨ�^�O(sh��)��socketʹ��׃?y��u)�non-blocking����(d��ng)��(du��)һ��(g��)non-blocking socket��(zh��)���x�����r(sh��)���������@��(g��)���ӣ�

��(d��ng)�Ñ��M(j��n)�̰l(f��)��read�����r(sh��)�����kernel�еĔ�(sh��)��(j��)߀�]�М�(zh��n)��ã���ô��������(hu��)block�Ñ��M(j��n)�̣��������̷���һ��(g��)error�����Ñ��M(j��n)�̽Ƕ��v �����l(f��)��һ��(g��)read����������Ҫ�ȴ��������R�Ͼ͵õ���һ��(g��)�Y(ji��)�����Ñ��M(j��n)���Д�Y(ji��)����һ��(g��)error�r(sh��)������֪����(sh��)��(j��)߀�]�М�(zh��n)��ã������������ٴΰl(f��)��read������һ��kernel�еĔ�(sh��)��(j��)��(zh��n)����ˣ��������ٴ��յ����Ñ��M(j��n)�̵�system call����ô���R�Ͼ͌���(sh��)��(j��)��ؐ�����Ñ��(n��i)�棬Ȼ�ء�
�������ԣ�nonblocking IO�����c(di��n)���Ñ��M(j��n)����Ҫ���������(d��ng)ԃ��kernel��(sh��)��(j��)���˛]�С�
(3) I/O��·��(f��)��
IO multiplexing�����҂��f��select��poll��epoll����Щ�ط�Ҳ�Q�@�NIO��ʽ��event driven IO��select/epoll�ĺ�̎�����چ�(g��)process�Ϳ���ͬ�r(sh��)̎������(g��)�W(w��ng)�j(lu��)�B�ӵ�IO�����Ļ���ԭ������select��poll��epoll�@��(g��)function��(hu��)�����݆ԃ��ؓ(f��)؟(z��)������socket����(d��ng)ij��(g��)socket�Д�(sh��)��(j��)���_(d��)�ˣ���֪ͨ�Ñ��M(j��n)�̡�
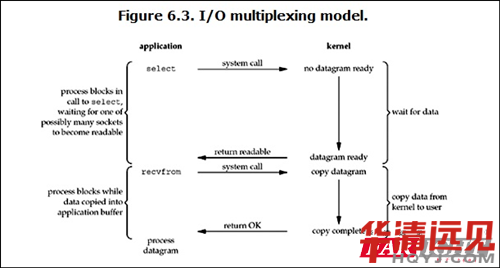
������(d��ng)�Ñ��M(j��n)���{(di��o)����select����ô����(g��)�M(j��n)�̕�(hu��)��block����ͬ�r(sh��)��kernel��(hu��)“�O(ji��n)ҕ”����selectؓ(f��)؟(z��)��socket����(d��ng)�κ�һ��(g��)socket�еĔ�(sh��)��(j��)��(zh��n)����ˣ�select�͕�(hu��)���ء��@��(g��)�r(sh��)���Ñ��M(j��n)�����{(di��o)��read����������(sh��)��(j��)��kernel��ؐ���Ñ��M(j��n)�̡�
�������ԣ�I/O ��·��(f��)�õ����c(di��n)��ͨ�^һ�N�C(j��)��һ��(g��)�M(j��n)����ͬ�r(sh��)�ȴ�����(g��)�ļ������������@Щ�ļ������������������������е�����һ��(g��)�M(j��n)���x�;w��B(t��i)��select()����(sh��)�Ϳ��Է��ء�
�����@��(g��)�D��blocking IO�ĈD�䌍(sh��)���]��̫��IJ�ͬ����(sh��)�ϣ�߀����һЩ����?y��n)��@����Ҫʹ�Ãɂ�(g��)system call (select �� recvfrom)����blocking IOֻ�{(di��o)����һ��(g��)system call (recvfrom)�����ǣ���select�ă�(y��u)��(sh��)����������ͬ�r(sh��)̎������(g��)connection��
�������ԣ����̎�����B�Ӕ�(sh��)���Ǻܸߵ�Ԓ��ʹ��select/epoll��web server��һ����ʹ��multi-threading + blocking IO��web server���ܸ��ã��������t߀����select/epoll�ă�(y��u)��(sh��)�����nj�(du��)�چ�(g��)�B����̎���ø��죬����������̎��������B�ӡ���
������IO multiplexing Model�У���(sh��)�H�У���(du��)��ÿһ��(g��)socket��һ�㶼�O(sh��)�óɞ�non-blocking�����ǣ����ψD��ʾ������(g��)�Ñ���process�䌍(sh��)��һֱ��block�ġ�ֻ���^process�DZ�select�@��(g��)����(sh��)block�������DZ�socket IO�oblock��
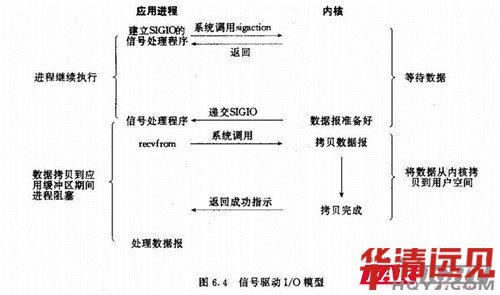
(4) ��̖(h��o)�(q��)��(d��ng)I/O
�����҂�?c��)��S�ӿ��M(j��n)����̖(h��o)�(q��)��(d��ng)I/O,�����bһ��(g��)��̖(h��o)̎������(sh��)���M(j��n)���^�m(x��)�\(y��n)�в�����������(d��ng)��(sh��)��(j��)��(zh��n)��Õr(sh��)���M(j��n)�̕�(hu��)�յ�һ��(g��)SIGIO��̖(h��o)����������̖(h��o)̎������(sh��)���{(di��o)��I/O��������(sh��)̎�픵(sh��)��(j��)��
(5) ����I/O
Linux�µ�asynchronous IO�䌍(sh��)�õú��١��ȿ�һ���������̣�
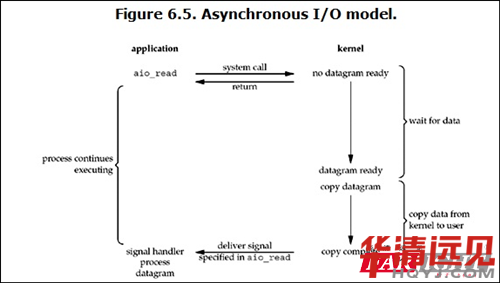
�����Ñ��M(j��n)�̰l(f��)��read����֮�����̾Ϳ����_ʼȥ���������¡�����һ���棬��kernel�ĽǶȣ���(d��ng)���ܵ�һ��(g��)asynchronous read֮����������(hu��)���̷��أ����Բ���(hu��)��(du��)�Ñ��M(j��n)�̮a(ch��n)���κ�block��Ȼ��kernel��(hu��)�ȴ���(sh��)��(j��)��(zh��n)����ɣ�Ȼ��(sh��)��(j��)��ؐ���Ñ��(n��i)�棬��(d��ng)�@һ�ж����֮��kernel��(hu��)�o�Ñ��M(j��n)�̰l(f��)��һ��(g��)signal�����V��read��������ˡ�
�������֣����Y(ji��)
(1) blocking��non-blocking�ą^(q��)�e
�{(di��o)��blocking IO��(hu��)һֱblockס��(du��)��(y��ng)���M(j��n)��ֱ��������ɣ���non-blocking IO��kernel߀��(zh��n)�䔵(sh��)��(j��)����r��(hu��)���̷��ء�
(2) synchronous IO�� asynchronous IO�ą^(q��)�e
���f��synchronous IO��asynchronous IO�ą^(q��)�e֮ǰ����Ҫ�Ƚo�����ߵĶ��x��POSIX�Ķ��x���@���ӵģ�
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
- An asynchronous I/O operation does not cause the requesting process to be blocked;
���ߵą^(q��)�e������synchronous IO��”IO operation”�ĕr(sh��)���(hu��)��process�����������@��(g��)���x��֮ǰ������blocking IO��non-blocking IO��IO multiplexing������synchronous IO��
���˕�(hu��)�f��non-blocking IO���]�б�block�����@���Ђ�(g��)�dz�“�ƻ�”�ĵط������x����ָ��”IO operation”��ָ�挍(sh��)��IO���������������е�recvfrom�@��(g��)system call��non-blocking IO�ڈ�(zh��)��recvfrom�@��(g��)system call�ĕr(sh��)�����kernel�Ĕ�(sh��)��(j��)�]�М�(zh��n)��ã��@�r(sh��)��(hu��)block�M(j��n)�̡����ǣ���(d��ng)kernel�Д�(sh��)��(j��)��(zh��n)��õĕr(sh��)��recvfrom��(hu��)����(sh��)��(j��)��kernel��ؐ���Ñ��(n��i)���У��@��(g��)�r(sh��)���M(j��n)���DZ�block�ˣ����@�Εr(sh��)�g��(n��i)���M(j��n)���DZ�block�ġ�
��asynchronous IO�t��һ�ӣ���(d��ng)�M(j��n)�̰l(f��)��IO ����֮��ֱ�ӷ�����Ҳ�������ˣ�ֱ��kernel�l(f��)��һ��(g��)��̖(h��o)�����V�M(j��n)���fIO��ɡ����@����(g��)�^���У��M(j��n)����ȫ�]�б�block��
(3) �NIOģ�͵ı��^

���l(f��)�F(xi��n)non-blocking IO��asynchronous IO�ą^(q��)�e߀�Ǻ����@�ġ���non-blocking IO�У��mȻ�M(j��n)�̴֕r(sh��)�g������(hu��)��block����������ȻҪ���M(j��n)��ȥ����(d��ng)��check�����Ү�(d��ng)��(sh��)��(j��)��(zh��n)������Ժ�Ҳ��Ҫ�M(j��n)������(d��ng)���ٴ��{(di��o)��recvfrom�팢��(sh��)��(j��)��ؐ���Ñ��(n��i)�档��asynchronous IO�t��ȫ��ͬ�����������Ñ��M(j��n)�̌�����(g��)IO�������o�����ˣ�kernel����ɣ�Ȼ�����������l(f��)��̖(h��o)֪ͨ���ڴ����g���Ñ��M(j��n)�̲���Ҫȥ�z��IO�����Ġ�B(t��i)��Ҳ����Ҫ����(d��ng)��ȥ��ؐ��(sh��)��(j��)��

 11�¾͘I(y��)�L(f��ng)�ư�ح���н�Y18k����н11k�����¾͘I(y��)���c(di��n)ʮ�¾͘I(y��)�L(f��ng)�ư�ح�x���A�� ��н�͘I(y��)�����ܶ����@���¾͘I(y��)�L(f��ng)�ư� | �͘I(y��)�΄�(sh��)���ԣ��A��W(xu��)�Ӆs���(sh��)��������T�ܿɐ� ���YҲ���� 8��н�Y���t��һ�N���������e�˼ҵij���T����һ�N���YҲ�����e�����¾͘I(y��)�L(f��ng)�ư�|��һ�Q���@��(g��)��Ƹ��(bi��o)��(zh��n)���Ҷ��M(j��n)�������A���h(yu��n)Ҋ90+�(xi��ng)Ŀ�@����������2021���
f(xi��)ͬ�����(xi��ng)Ŀ���A���h(yu��n)Ҋ�s�@2021�vӍ��������ȿڱ�Ӱ����I(y��)����Ʒ�A���h(yu��n)Ҋ��������2021����h���k��У��Ϣ�W(xu��)�ƺ���(li��n)����ůͬ�й���(chu��ng)�ѿ� 2019�A���h(yu��n)Ҋ�����������(hu��)���ع�������УAI�˹����܌W(xu��)�ƽ��O(sh��) �A���h(yu��n)Ҋ�˹������Y���A���h(yu��n)Ҋ���������Ĵ�ʡ��(li��n)�W(w��ng)���(hu��)���s�@��(y��u)����I(y��)����
11�¾͘I(y��)�L(f��ng)�ư�ح���н�Y18k����н11k�����¾͘I(y��)���c(di��n)ʮ�¾͘I(y��)�L(f��ng)�ư�ح�x���A�� ��н�͘I(y��)�����ܶ����@���¾͘I(y��)�L(f��ng)�ư� | �͘I(y��)�΄�(sh��)���ԣ��A��W(xu��)�Ӆs���(sh��)��������T�ܿɐ� ���YҲ���� 8��н�Y���t��һ�N���������e�˼ҵij���T����һ�N���YҲ�����e�����¾͘I(y��)�L(f��ng)�ư�|��һ�Q���@��(g��)��Ƹ��(bi��o)��(zh��n)���Ҷ��M(j��n)�������A���h(yu��n)Ҋ90+�(xi��ng)Ŀ�@����������2021���
f(xi��)ͬ�����(xi��ng)Ŀ���A���h(yu��n)Ҋ�s�@2021�vӍ��������ȿڱ�Ӱ����I(y��)����Ʒ�A���h(yu��n)Ҋ��������2021����h���k��У��Ϣ�W(xu��)�ƺ���(li��n)����ůͬ�й���(chu��ng)�ѿ� 2019�A���h(yu��n)Ҋ�����������(hu��)���ع�������УAI�˹����܌W(xu��)�ƽ��O(sh��) �A���h(yu��n)Ҋ�˹������Y���A���h(yu��n)Ҋ���������Ĵ�ʡ��(li��n)�W(w��ng)���(hu��)���s�@��(y��u)����I(y��)����

